

-


数据库
站-
热门城市 全国站>
-
其他省市
-
-

 15692118659
15692118659
 小职
2021-01-04
来源 :https://blog.csdn.net/weixin_42217502/article/deta
阅读 3213
评论 0
小职
2021-01-04
来源 :https://blog.csdn.net/weixin_42217502/article/deta
阅读 3213
评论 0
摘要:本文主要向大家介绍了数据库SQL Server学习之SQL Server数据库知识点总结,通过具体的内容向大家展现,希望对大家数据库SQL Server学有所帮助。
本文主要向大家介绍了数据库SQL Server学习之SQL Server数据库知识点总结,通过具体的内容向大家展现,希望对大家数据库SQL Server学有所帮助。

1,索引
1聚集索引(Clustered Index)特点
聚集索引的叶节点就是实际的数据页
聚集索引中的排序顺序仅仅表示数据页链在逻辑上是有序的。而不是按照顺序物理的存储在磁盘上
行的物理位置和行在索引中的位置是相同的
每个表只能有一个聚集索引
聚集索引的平均大小大约为表大小的5%左右
2非聚集索引 (Unclustered Index) 特点
非聚集索引的页,不是数据,而是指向数据页的页。
若未指定索引类型,则默认为非聚集索引。
叶节点页的次序和表的物理存储次序不同
每个表最多可以有249个非聚集索引
在非聚集索引创建之前创建聚集索引(否则会引发索引重建)
2,联合(Union联合查询)
1条件
联合结果集不受被联合的多个结果集之间的关系限制,不过使用UNION仍然由两个基本的原则需要遵守:
SELECT
TeacherName
,Age
,Address
FROM [BlogDemo2].[dbo].[Teacher]
Union --联合查询
SELECT
StudentName
,Age
,Address
FROM [BlogDemo2].[dbo].[Student]
每个结果集必须是由相同的列数;
每个结果集的咧必须类型相同,即结果集的每个对应列的数据类型必须相同或者能够转换为同一种数据类型。
2Union和Union All两种方式
**区别:**union有去重复的功能,union all没有去重复的功能,所以union的效率会低点,如果查询的结果集没有想要去重或者联合表中不存在重复数据,建议使用union all操作。
3,连接查询(内连接、左连接、右连接)
**概念:**根据两个或多个表的列之间的关系,从这些表中查询数据。
**目的:**实现多个表查询操作。
1连接语法格式:
FROM join_table join-Type join_table [ON(join_condition)]
其中join_table指出连接参与的连接操作的表名,连接可以对同一个表操作,叫做自连接,也可以对多表操作。join_type之处连接类型,join_condiction指出连接条件。
2内连接(INNER JOIN)
内连接只显示满足条件的!
**等值连接:**连接条件中使用=运算符,其查询结果中列出被连接表中的所有列,包括其中的重复列。
**不等连接:**在连接条件中使用除等号之外运算符(>,<,<>,>=,<=,!>和!<)
**自然连接:**连接条件和等值连接相同,但是会删除连接表中的重复列。
3外连接
左连接:返回左表中的行,如果左表中行在右边中没有匹配行,则结果中右表的列返回空值。
**右连接:**与做左连接相反
**全连接:**返回所有行,没有的返回空值。
4交叉连接(笛卡尔积)
概念:不带where条件子句,它将会返回被连接的两个表的笛卡尔积,返回结果的行等于两个表行数的乘积。 (例如:T_student和T_class,返回4*4=16条记录),如果带where,返回或显示的是匹配的行数。
4,分组
1Group By +字段:
根据表中的字段自动将数据分组。
注意:在select指定的字段要么就要包含在Group By语句的后面,作为分组的依据;要么就要包含在聚合函数中。
2Order By +字段 +desc
根据表中某一列名排序数据。默认升序排列(asc升序),需要降序排列时使用desc。
3聚合函数
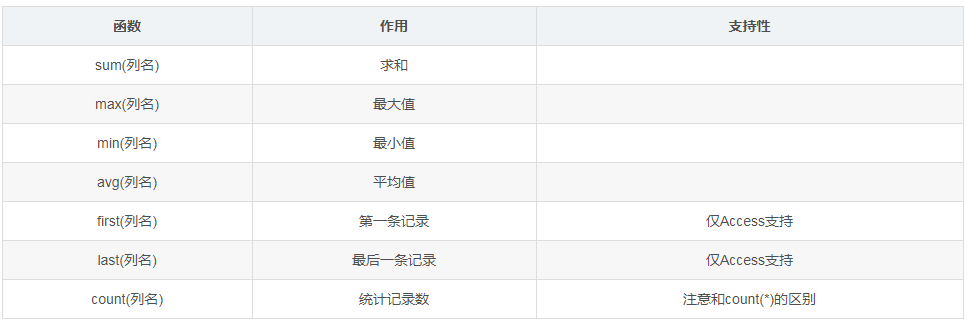
5,数据库优化
1,不要使用select *
在select 中指定所需要的列,将带来的好处,
减少内存耗费和网络的宽带
更安全
给查询优化器机会从索引器读取所有需要的列
2,in和not in要慎用,否则会导致全表扫描
3、对于连续的数值,能用 between 就不要用 in
4、使用exists 代替 in
select num from a where exists(select 1 from b where num=a.num)
5、is null或is not null操作
应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描, 尽量让表中不存在null值。
select id from t where num is null (慢)
可以在num上设置默认值0,确保表中num列没有null值,然后这样查询:
select id from t where num = 0(快)
6、用union替换or(适用于索引列)
用union替换where子句中的or将会起到较好的效果。对索引列使用or将造成全表扫描。
7、优化group by
提高group by语句的效率,可以通过将不需要的记录在group by之前过滤掉。
(低效)select [job],avg([sal]) from [emp] group by [job] having job='PRESIDENT' or job='MANAGER';
(高效)select [job],avg([sal]) from [emp] where [job]='PRESIDENT' or job='MANAGER' group by [job];
8、<及>操作
大于或小于一般情况不用调整,因为它有索引就会采用索引查找,但有的情况下可以对它进行优化。如一个表有100万记录,那么执行>2与>=3的效果就有很大区别了。
(低效)select * from [emp] where [deptno]>2;
(高效)select * from [emp] where [deptno]>=3;
9、应尽量避免在 where 子句中使用 or 来连接条件
如果一个字段有索引,一个字段没有索引,将导致引擎放弃使用索引而进行全表扫描
select id from t where num=10 or Name = 'admin'
可以这样查询:
select id from t where num = 10
union all
select id from t where Name = 'admin'
10、尽量避免在where子句中对字段进行表达式操作,否则将导致全表扫描。
select id from t where num/2=100
应改为:
select id from t where num=100*2
11、尽量避免在where子句中对字段进行函数操作,否则将导致全表扫描。
select id from t where substring(name,1,3)='abc'
应改为:
select id from t where name like 'abc%'
12、尽量避免使用前置百分号。
select id from t where name like '%abc%'
6,分页
top+嵌套查询:select top 10 * from 表 where id not in(select top 20 id from 表 order by id)order by id,(使用之前需要排序)
ROW_NUMBER()开创函数,使用ROW_NUMBER()建立视图,
建立视图:
create view View_Page
as
select *,ROW_NUMBER() over (order by id) as rowindex from 表
获取数据:
select * from View_Page where rowindex>=21 and rowindex<=30
offset fetch ,用之前需要将表排序。介绍:offset x rows >=跳过之前的x行 fetch next y rows => 取之后的y行。使用sql server 2008以上版本。
select * from 表 order by id offset 20 rows fetch next 10 rows only;
另外在ASP.NET MVC下借助EntityFramework中提供了两个分页的方法,Skip()、Take(),使用这两个方法前要进行OrderBy()操作。
db.View_Movies_yu.OrderBy(md=>md.Mid).Skip((page-1)*limit).Take(limit)
.ToList();
7,存储过程procedure
定义:数据库中内置的程序段,当执行存储过程时,会依次的执行其中的SQL代码。类似程序中的函数。手动执行存储过程使用exec 符号
作用:
允许我们在数据库中封装一些业务逻辑。
速度快,存储过程少了依次编译过程,直接写语句要高效率。
安全,sqlpara方式进行参数传递,可以防止SQL注入式攻击。
使用
可以带参数,@参数名称 类型,
create procedure pr_queryStudent
@name nvarchar(50)
as
select * from dbo.Students where name=@name
go
exec pr_queryById_student '张三'
可以返回值return,只能返回值类型,只能返回一个结果,并且结果必须是整型。
可以返回值output,
create proc pr_insert_students_output
@name nvarchar(50),@age int,@createtime datetime,
@newid int output,@nname nvarchar(50) output
as
insert into Students values(@name,@age,@createtime)
--全局变量@@identity获取新插入数据库的数据主键
set @newid=@@IDENTITY
set @nname=@name
go
declare @newid int,@nname nvarchar(50)
exec pr_insert_students_output '张三',20,'2020-10-31',@newid output,@nname output
select @newid as nid,@nname as nname
8,触发器trigger
定义:一种特殊的存储过程,内部封装的也是一个程序段,它和存储过程不同的是触发器是自己调用,不需要认为调用。
两张系统临时表
deleted:存放旧数据(刚被删除的数据)
inserted:存放新数据(刚被插入的数据)
注意:触发器没有参数
--当用户删除的时候,用户的图书也要删除。
create trigger tr_delete_studnets
on Students after delete
as
declare @oldid int
select @oldid=ID from deleted
--删除图书
delete from book WHERE sid=@oldid
go
总结:在实际开发中,触发器使用的频率低。当一个表基本不会被改动时,使用触发器
9,游标
定义:游标是T-SQL支持的一种对象,可以用它来处理查询返回的结果集中的各行,以指定的顺序一次只处理一行。它可以定位到结果集中的某一行,多数据进行读写,也可以移动游标定位到你所需的行中进行操作。
1.声明游标
declare 游标名 cursor
for
select 要获取的列名 from 表名
2.打开游标
open 游标名
3.从游标中读取查询数据,每一次可以读取一条记录。
fetch next from 游标名 into 存放要读取数据的变量
4.验证fetch是否成功获取数据
如果@@fetch_status=0则成功获取数据,否则没获得。
5.关闭游标
close 游标名
6.释放游标
deallocate 游标名
表中使用
--1.声明游标,基于查询
declare usI cursor
for
select * from UserInfo;
declare @id int;
declare @name nvarchar(10);
declare @pwd char(32);
--2.在使用之前必须打开游标
open usI;
--3.从游标中读取查询数据,每次可以读取一条记录.使用fetch时,声明的变量数目必须与所选列的数目相同
fetch next from usI into @id,@name,@pwd;
--4.注意fetch并不一定能够获取实际的数据
while @@FETCH_STATUS=0
begin --获取成功时
print @id;
print @name;
print @pwd;
fetch next from usI into @id,@name,@pwd;
end
--5.游标使用完毕一定要关闭
close usI;
--6.释放游标
deallocate usI;
10,视图
视图是一个查询所定义的虚拟表,他与物理表不同的是,视图中的数据没有物理的表现形式,除非你为其创建一个索引;如果查询一个没有索引的视图,Sql server 实际访问的就是基础表。
优点:
简化查询。增加数据的保密性
缺点:
增加了数据库的维护成本。视图只是简化了查询,但是并不能加快查询速度。
11,临时表
临时表与永久表相似,但临时表存储在tempdb中,当不再使用时会自动删除。临时表有两种:本地和全局。
特点:
本地临时表:用户在创建表的时候添加了“#”前缀,其特点是根据数据库连接独立,只有创建本地临时表的数据库连接时才有权访问该表;
不同的数据库连接中,创建的本地临时表虽然名字相同,但是这些表不存在任何关系。
真正的临时表利用了数据库临时空间,有数据库自动维护,因此节省了表空间。而由于临时表一般利用虚拟内存,大大减少了硬盘的I/O次数,提高了系统效率。
临时表在事务完毕或者会话完毕 数据会自动清空,不必记得用完后删除。
本地临时表
以单个字符#打头;它们只对当前用户连接可见;当实例断开后删除。
数据库连接A:
create table #temp
{
id int,
name nvarchar(50),
age int
}
//可见
select * from #temp
全局临时表:
以两个字符##打头;创建后,任何连接都是可见的,当所有引用该表的数据库连接从SQL SERVER 断开时被删除。
用途:
临时表的优化一般使用在子查询角度的情况下,也就是嵌套查询。
select * from Students where id in(select top 5 id from Students)
使用临时表
select top 5 id into #temp from Students
select * from Students where id in (select id from #temp)
**总结:**使用子查询。当你需要从一个结果集中获取数据的时候
12,事务
事务是单个的工作单元。事务是在数据库上按照一定的逻辑顺序执行的任务序列,既可以由用户手动执行,也可以由某种数据库自动执行。
事务特性:
原子性:事务必须是一个自动工作的单元,要么全部执行,要么全部不执行
一致性:事务结束的时候,所有的内部数据都是正确的。
隔离性:并发事务时,各个事务不干涉内部数据,处理的都是另外一个事务处理之前或之后的数据。
持久性:事务提交之后,数据是永久的,不可再回滚。
事务分类:
自动提交事务: 是SQL Server默认的一种事务模式,每条Sql语句都被看成一个事务进行处理,
显示事务: T-sql标明,由Begin Transaction开启事务开始,由Commit Transaction 提交事务、Rollback Transaction 回滚事务结束。
隐式事务: 使用Set IMPLICIT_TRANSACTIONS ON 将将隐式事务模式打开,不用Begin Transaction开启事务,当一个事务结束,这个模式会自动启用下一个事务(形成了事务链),只用Commit Transaction 提交事务、Rollback Transaction 回滚事务即可。
事务隔离
隔离级别用于决定如何控制并发用户读写数据的操作。
读操作默认使用共享锁;写操作需要使用排它锁。
读操作能够控制他的处理的方式,写操作不能控制它的处理方式。
13,锁
NOLOCK(不加锁) 此选项被选中时,SQL Server 在读取或修改数据时不加任何锁。 在这种情况下,用户有可能读取到未完成事务(Uncommited Transaction)或回滚(Roll Back)中的数据, 即所谓的“脏数据”。
HOLDLOCK(保持锁)
此选项被选中时,SQL Server 会将此共享锁保持至整个事务结束,而不会在途中释放。
UPDLOCK(修改锁)
此选项被选中时,SQL Server 在读取数据时使用修改锁来代替共享锁,并将此锁保持至整个事务或命令结束。使用此选项能够保证多个进程能同时读取数据但只有该进程能修改数据。
TABLOCK(表锁)
此选项被选中时,SQL Server 将在整个表上置共享锁直至该命令结束。 这个选项保证其他进程只能读取而不能修改数据。
PAGLOCK(页锁)
此选项为默认选项, 当被选中时,SQL Server 使用共享页锁。
TABLOCKX(排它表锁)
此选项被选中时,SQL Server 将在整个表上置排它锁直至该命令或事务结束。这将防止其他进程读取或修改表中的数据。
锁定
在多用户都用事务同时访问同一个数据资源的情况下,就会造成以下几种数据错误。
更新丢失:多个用户同时对一个数据资源进行更新,必定会产生被覆盖的数据,造成数据读写异常。
不可重复读:如果一个用户在一个事务中多次读取一条数据,而另外一个用户则同时更新啦这条数据,造成第一个用户多次读取数据不一致。
脏读:第一个事务读取第二个事务正在更新的数据表,如果第二个事务还没有更新完成,那么第一个事务读取的数据将是一半为更新过的,一半还没更新过的数据,这样的数据毫无意义。
幻读:第一个事务读取一个结果集后,第二个事务,对这个结果集经行增删操作,然而第一个事务中再次对这个结果集进行查询时,数据发现丢失或新增。
然而锁定,就是为解决这些问题所生的,他的存在使得一个事务对他自己的数据块进行操作的时候,而另外一个事务则不能插足这些数据块。这就是所谓的锁定。
死锁
这样互相等待对方释放资源,造成资源读写拥挤堵塞的情况,就被称为死锁现象,也叫做阻塞。
然而数据库并没有出现无限等待的情况,是因为数据库搜索引擎会定期检测这种状况,一旦发现有情况,立马选择一个事务作为牺牲品。牺牲的事务,将会回滚数据。
如何解决死锁:
按照同意顺序访问数据库资源
保持事务的简短
尽量减少数据库的并发量
尽量不要在食物中要求用户响应
关注“职坐标在线”(Zhizuobiao_Online)公众号,免费获取学习视频资料、技术就业咨询

 喜欢 | 0
喜欢 | 0
 不喜欢 | 0
不喜欢 | 0


您输入的评论内容中包含违禁敏感词
我知道了

请输入正确的手机号码
请输入正确的验证码
您今天的短信下发次数太多了,明天再试试吧!
我们会在第一时间安排职业规划师联系您!
您也可以联系我们的职业规划师咨询:

版权所有 职坐标-一站式AI+学习就业服务平台 沪ICP备13042190号-4
上海海同信息科技有限公司 Copyright ©2015 www.zhizuobiao.com,All Rights Reserved.
 沪公网安备 31011502005948号
沪公网安备 31011502005948号






 资料领取
资料领取

 答疑解惑
答疑解惑

 技术交流
技术交流

 职业测评
职业测评

 面试技巧
面试技巧

 高薪秘笈
高薪秘笈




